高级策略闭环实盘闭环
查看详情AI量化全流程高级班
以策略闭环为目标,打通模型优化、增量学习、自动化部署和智能风控的完整链路。
4.9 (234评价)856人学习12小时6节
以策略闭环为目标,打通模型优化、增量学习、自动化部署和智能风控的完整链路。
¥6,999
结合 2026 年最新的 AI agent 数据接入实践,解释为什么量化研发应该先建设可查询、可审计、可限权的数据接入层,再谈更复杂的 Agent 编排。
如果你想把这篇文章里的方法系统化学习,可以从这些课程继续深入。
以策略闭环为目标,打通模型优化、增量学习、自动化部署和智能风控的完整链路。
以策略闭环为目标,打通模型优化、增量学习、自动化部署和智能风控的完整链路。
聚焦 AI 大模型在量化研发中的提效场景,覆盖因子代码孵化、研报转策略、向量化改写、回测系统搭建与生产级代码协作。
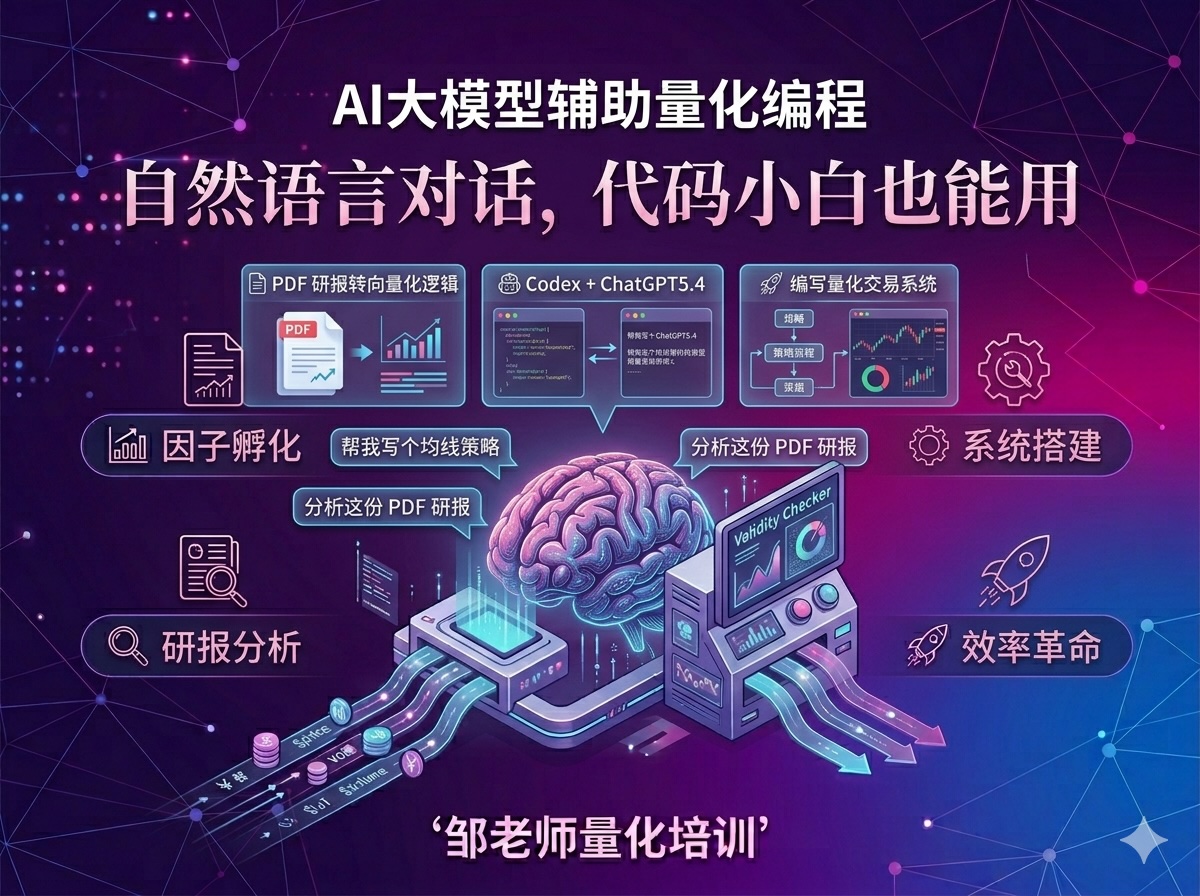
聚焦 AI 大模型在量化研发中的提效场景,覆盖因子代码孵化、研报转策略、向量化改写、回测系统搭建与生产级代码协作。
电脑操作能力一旦进入量化研发,最危险的误解就是把它当成更会点鼠标的脚本;真正该先设计的,其实是哪些环节能自动值守、哪些证据必须留档、哪些动作必须在固定工位完成。
量化团队把 agent 用进开发流后,最容易丢失的不是提示词,而是每次运行到底做了什么、怎样验证、谁在什么时候接手。
当量化代码开始由 Agent 参与生成与修改,团队最缺的通常不是更多模型选项,而是一套能被版本控制、代码审阅和长任务恢复共同消费的研发合同。